TSM - The AI Trends (And Hype) For The Coming Year
2024-01-17 09:33:04 ET
Summary
- Large language models aka LLMs and generative AI aka GenAI are reshaping various industries and rewriting life as we know it.
- Monetization of GenAI has primarily focused on B2B revenue streams, but subscription-based models and the "GPT Store" show promise for individual users.
- Hardware and software design, AI workflow enhancers, and applied AI opportunities are key areas to watch in the GenAI space.
One of the main stories, if not the story of 2023 for the investing world, has been the advent of large language models ("LLMs"), their usage as the engine of generative AI (GenAI) and how, slowly but surely, GenAI has begun to rewrite life as we know it. Understandably, in a period of high uncertainty that such an upheaval brings along for the ride, it becomes exceedingly difficult to separate the flash from the substance. We spent a significant portion of the year parsing through various GenAI offerings, and as we reflect, we wanted to share our assessment of the state of GenAI, peel back the curtain a bit on how close it really is to the era-defining messiah of dream or nightmare, and set the stage for the coming year from a business perspective for the major players in this space.
Force multipliers and value-adds
The magic phrase that's been in our heads the last several months concerning AI's transformative ability is force multiplier . It smacks of corp-speak, admittedly, but from a first-principles standpoint, it pretty accurately describes what generative AI has made available to the masses. If one would forgive taking the mechanical analogy to its extreme, it's akin to what the printing press did for the written word's proliferation. The key to these two breakthroughs, though, is that multiplier effect, how the (ongoing) work of a few provides benefits to orders of magnitude more individuals. Today's LLMs can all trace their roots to the seminal paper on the transformer model, " Attention Is All You Need ," with just eight listed authors.
Doing a lot with a little is a rather broad-sweeping thesis, we will admit, especially with so much of the fundamental technology still in flux. The huge question we ask every time there's some new business-source news piece talking about AI is: what is the monetization story? So much emphasis has been given to creating bigger and better models at all costs, eerily echoing the hyper-growth startup model of the last decade: users first, revenue later. With the underlying LLM advancements quickly approaching steady state, converting users to revenue is more important now than ever to offset the massive infrastructural costs required to train and host such models.
From where we're sitting, much of the early monetization has focused on B2B (or more accurately, "dev-to-dev") type revenue streams. Every AI player is all too eager to hand out API keys like candy, but API keys aren't the kind of thing an average individual is all too interested in, along with things like the "price per token" that API access is billed by, so most folks will only be experiencing the AI "magic" through some other modality: chatbot, copilot, behind-the-scenes feature implementation, etc. Some of that indirection also stems from the need to provide extensive grounding to prevent hallucinations and toxicity, either "spontaneous" or provoked by a bad actor. Thus, at this stage, other developers seem like the safest individuals to whom the model authors can trust direct model access (along with making it easier to control access by auditing inputs and revoking keys for proven bad actors).
That said, OpenAI has shown some promise for subscription-based "AI-as-a-service" revenue models, given the positive feedback individuals using ChatGPT Plus, powered by GPT-4, have provided on the experience. We aren't convinced this kind of "premium chatbot" modality is a revenue source that can scale solely by catering directly to individuals; after a while, you'll start to see "password sharing" take hold and growth will stagnate. There is one new development, also from OpenAI, that we think has potential to push monetization further: the "GPT Store." The parallels to the introduction of the smartphone and the "App Store" are apt, don't fix what's not broken when it comes to trusting the wisdom (and the creativity) of the masses. Democratize the refinement process, let individuals vote with their time and their wallets, take the feedback and iterate the entire cycle.
The business angle
Hardware: the nuts-and-bolts
As magical as they may seem, the essence of an LLM is code performing large amounts of mathematical operations on specialized silicon , the never-ending cycle of modern computer engineering. The code and the silicon are in a kind of "co-evolutionary" phase, where each tries to play to the other's strength while remaining flexible enough to accommodate something better in the future.
Hyperscalers and model developers lean on GPUs as their preferred accelerator backbone, likely because of the ability of the manufacturers like Nvidia Corporation ( NVDA ) to cram massive amounts of VRAM onto the cards, minimizing the need to split workloads across multiple accelerators; and to offer a vertically-integrated development experience with libraries like CUDA. It's an experience that's nearly impossible to replicate, which explains why Nvidia has such a stranglehold in this space. Given Nvidia basically created and continues to lead the GPU industry, we see no reason they won't be able to at least "grow into" their currently rich valuation, if not to surpass it.
Meanwhile, while the actual chip designers are getting the bulk of the attention, they can't really execute without the help of fabrication equipment , called out at the end of November as the proverbial "picks and shovels" of the AI gold rush. This part of the stack is the best. Boring but churning out cash. As value investors, the equipment makers have all the hallmarks we love to see: low P/E, high return on equity and little-to-no net debt. A cursory glance at the big names shows that Applied Materials, Inc. ( AMAT ) is the highest-rated of the bunch by Seeking Alpha's quant model, and a name we wouldn't mind adding to our own portfolio sometime soon.
Cloud: The AI backbone
AI's massive appetite for compute power has perversely come as a boon for the big cloud providers, giving them both the ability to sell on AI accelerator units to end-users as well as packaging up their own LLMs in APIs and charging by the token for integration into bigger solutions. Where all the infra costs for AI within cloud were previously massive money pits for hyperscalers, buoyed by LLMs from Microsoft ( MSFT ) and Alphabet ( GOOG , GOOGL ) aka Google , they now have product after product backed by LLM-powered solutions running exclusively on their cloud hardware, helping them to actually monetize all of that outlay.
The spoonful of sugar: AI Workflow enhancers
Allowing users to perform the same amount of work for way less effort is never a bad investment, all the more so if you can ensure a sticky offering with high product loyalty. Case-in-point: Slack, which has its army of devoted users even as the pure product offering appears to be nothing more than a threaded chat app with plugin support. Here are a few broad categories pertaining to model development:
-
Libraries for describing a model topology and a training regimen
-
Repositories for different pieces of the AI lifecycle: datasets, model cards, different training tasks
-
Streamlined approaches for legally requisitioning data in a way that respects original content creators' wishes
-
Efficient storage and hosting for datasets and trained models.
Along with the hyperscalers, data storage providers like Couchbase ( BASE ), MongoDB ( MDB ) and especially Snowflake ( SNOW ) are likely in the best position to add value at this part of the stack. ML data needs are already massive and showing no signs of shrinking; having visibility and auditability of such piles of data will be crucial to working in this space. These names are growth stocks, though, with high P/Es or even pre-revenue, so their fates may be heavily tied to the AI space as a whole taking off. The ML ecosystem HuggingFace also fills this area very nicely with their suite of off-the-shelf solutions for a wide range of tasks; with big-name models like LLaMA and Phi-2 hosted there, it wouldn't be a surprise to see a big tech name end up acquiring them.
AI Toolkit enhancements
Starting from base models, the ability to take them and either enhance their training or integrate them into larger applications is another place where value adds would be a massive benefit to developers, especially if scaling from prototype to production is as frictionless as possible. Specific tasks to focus on include:
-
Infrastructure for fine-tuning LLMs, especially parameter-efficient fine-tuning
-
Efficient integration with external data sources, either for "retrieval augmented" workflows or for orchestration workflows
-
Bolt-on solutions for ensuring compliance with ethical and privacy guidelines, defending users from toxic responses or maliciously-prompted AI actors, etc.
OpenAI's GPT Store is the clearest example of building such capabilities as close to the LLM itself as possible without full-on vertical integration. HuggingFace has some solutions for fine-tuning, and the LangChain library offers unified integration points for LLMs and other various data sources. We aren't familiar with any other public or soon-to-be-public names doing anything in this space, but by this stage of the game, it's tricky to offer up something that adds more value than just locking in to a particular model's ecosystem. Derek worked in risk modeling at a fintech company, and before the company pivoted to API and data provision, it certainly felt like the sell of "buy our terminal and get various third-party risk models integrated if you subscribe to them " got less and less traction as time went on.
Applied AI
And at the top (or the bottom, however you choose to look at it), we have the applied AI opportunities, actually using an AI to do something beneficial that adds value versus the non-AI alternatives. It's hard to say this even qualifies as a bona fide business angle, given the maxim "if everyone is special, then no one is." Perhaps you can consider new business opportunities like "applied AI consulting," domain-specific virtual assistants powered by AI (we've seen at least two major companies run ads over the past weekend featuring an AI-powered assistant), or that there is an asymmetry in which industries will benefit from applied AI and target the ones with the most to gain from AI adoption.
From an end-user standpoint, however, the opportunity comes from being able to "bolt on" AI enhancements to an already entrenched product offering, akin to the "making people more efficient" point we made previously. Case in point: Microsoft's Copilot for Office, which has received high praise from users and can take advantage of Microsoft's massive existing user base to offer a competitive price point per seat. In the modern subscription-based SaaS world, AI really has the potential to a) bring in new revenue, b) preserve an existing subscriber base, or even c) siphon subscribers away by dramatically undercutting the effort required to perform tasks with a given software application (who needs Photoshop from Adobe ( ADBE ) when you can prompt DALL-E or Midjourney?).
At least one analyst has called out the existential threat of AI to the SaaS business model, with Adobe in the most immediate peril. While our view is more moderate from the industry perspective, we do believe that for the biggest SaaS names, the time is now to find ways to either add value for existing subscribers or add savings for the existing tech stack with the current AI offerings, before the next iteration either does their job better or makes a competing product child's play to produce.
Another arena where a lot of words are being written but we can't find hard data to back it up is the effect on the "gig economy" as personified in platforms like Fiverr International ( FVRR ). Cursory Google searching turns up lots of short blog posts (which look AI-generated themselves) opining about how GenAI could transform the gig marketplace, analysts believing the headwinds are overblown, tips from people on how to become a gig worker selling AI-generated content, even stories from people complaining that their Fiverr hires are just providing AI-generated content when they specifically went to Fiverr to find human-generated content.
As with the other disruptions in this space, we'll likely see the marketplaces and services offered co-evolve to ensure customers are getting the product they want and that workers are able to find their target clientele regardless of their toolkit.
Pitfalls
Now that we've laid out the thesis and shown it in action (or not), we should highlight the most glaring areas where hype has the potential to dominate the airwaves over the actual technological advancements and the new opportunities available for AI players as a result.
Practicality: the "state-of-the-art" fallacy
Whether trying to impress shareholders or grant committees, the most headline-catching stories about new AI models always quote some modicum of improvement on a benchmark here or a dataset there, but it's easy to forget two major considerations: the realism and the practicality of the scenario being presented. As Derek's current company dove into AI with both feet, he read through Designing Machine Learning Systems by Chip Huyen, a well-crafted engineer's perspective on how to build and apply ML systems for those versed in computers but not necessarily the deep math required for modern ML. One passage sticks out from a section on model selection:
"Researchers often only evaluate models in academic settings, which means that a model being state of the art often means that it performs better than existing models on some static datasets . It doesn't mean that this model will be fast enough or cheap enough for you to implement. It doesn't even mean that this model will perform better than other models on your data."
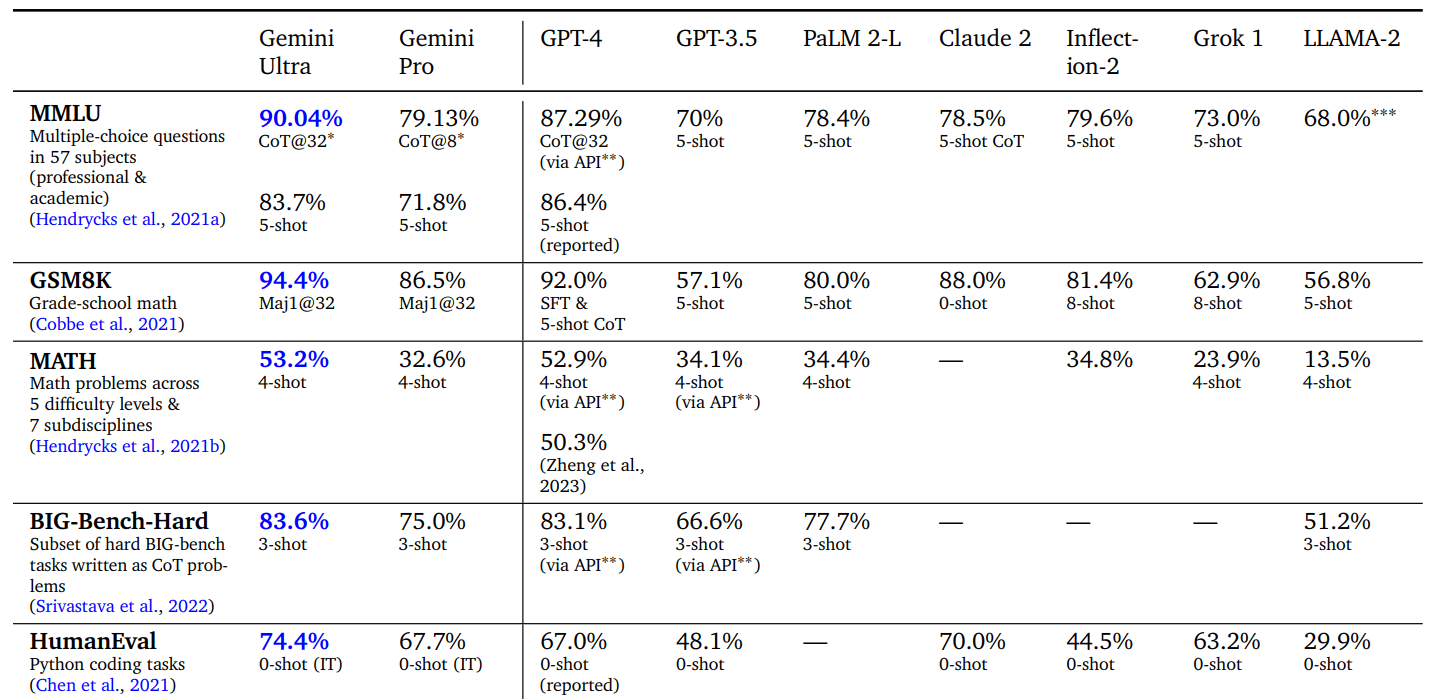
While this advice was largely offered in the context of building a standalone, self-contained model, the premise still applies to AI-based solutions as a whole. As Google's Gemini announcement demonstrated, this kind of showcasing can make its way into product releases as well as publications. While hyperscalers like Google and Microsoft offer to alleviate some of the issues of implementation by providing APIs, that still does not address the issue of whether an LLM is even the right tool for the job.
Subset of various text-based benchmark performances reported by Google in their Gemini report. Note that some of the improvements over GPT-4 are on the order of less than one percentage point. (Google Gemini report)
{kind=link}
The old saying goes that "when you have a golden hammer, every problem looks like a nail." It's not a far cry to say that many purported AI-based applications are not going to end up panning out, or if they do, they're actually worse dollar-for-dollar than a non-AI or even a simpler-ML-based solution.
Grounding
In order to make an LLM useful for a focused task or a user-facing interface, a lot of effort must be spent on creating what is called the "system prompt," a sometimes verbose section of text, hidden from the user, which contains a significant number of instructions and context intended to help keep the output focused and protecting the user from bad responses. Looking at a system prompt from one of the Gemini demos showcasing the model's multimodal reasoning, we see that the natural language "code" used to produce output for the user includes:
-
"Role setting", a kind of context where the model is told to act as an expert on a subject in order to ground its responses
-
Multiple calls to Gemini, wherein the model has processed text and images uploaded by the user
-
A detailed description of the outputs the model should generate under various circumstances, usually in some kind of structured data format
-
Additional contextual instructions regarding tone, verbosity, etc.
System prompt from the Gemini demo "Explaining reasoning in math and physics". Note the verbosity of the system prompt, the comments that indicate at least five pieces of information are filled in by Gemini out-of-band, the "move selection" approach towards the bottom, and the tonality markers. (Google Official YouTube)
{kind=link}
When all is said and done, the user's actual typed input may only make up a small portion of what gets sent to the model.
Model capabilities
Most of the AI-based interactions that claim to be able to call out to external resources and perform "agent-like" behaviors are actually being propped up by a layer of "simpler" code which is prompting the LLM and using its responses to perform actions. Derek made the analogy to "lifelines" from Who Wants to be a Millionaire, which has tested well with domain experts in Applied ML. Case-in-point: the following documentation snippet from OpenAI's "Function calling" feature, which was integral to the end-to-end demo at the end of OpenAI's Dev Days keynote (emphasis ours):
"...you can describe functions and have the model intelligently choose to output...arguments to call one or many functions. The Chat Completions API does not call the function ; instead, the model generates [structured data] that you can use to call the function in your code."
That being said, OpenAI also notes that this capability is baked in to the model versus needing to be explained via few-shot examples, such as with a library like LangChain. They do admit that the user's function definitions count against the context limit of the model, so there is still room for improvement in reducing the overhead required.
Scalability
The state-of-the-art is rapidly becoming more difficult to push forward by throwing more resources at the problem. GPT-4 and Gemini Ultra both have alleged parameter counts numbering above 1.5 trillion, which is five to ten times the parameter counts of previous-generation LLMs. That cadence of parameters cannot continue without some kind of sacrifice to either speed (already a problem when it comes to training) or precision. Physical compute resources, and the raw materials necessary to fuel them, are also feeling the strain from the blitz scaling, as best illustrated by Microsoft's renewed push for expansion of nuclear power.
Perhaps, then, in the future engineers won't be asking what kind of ML architecture, but rather will be asking how big of an LLM their application needs. This realization may have been the impetus for Google to release different-sized versions of Gemini and Microsoft to roll out Phi-2, providing more options to users and developers without needing (or assuming) hyperscaler-grade resources to get started.
To wit: we used Google AI Studio to ask Gemini Pro to perform a personal finance bookkeeping task for us - extracting data from CSVs and Excel spreadsheets formatted as tab-delimited tables and converting it to a double-entry accounting format - and with minimal ("zero-shot") context, it performed quite admirably, although it still had trouble with different-but-similar column names and more complex instructions like "sum the values of duplicate symbols". It will be an interesting experience to see if longer contexts on smaller models allow complex system prompts to run on a model around 3 billion parameters and produce little-to-no hallucination.
Legal Challenges
With the public domain slowly but surely creeping closer to the 20th century troves of "rich media" (i.e. - not just text and static imagery), licensing content libraries to train AI may be a preferable fate for names like Steamboat Willie . The lawsuit from the New York Times ((NYT)) against Microsoft and OpenAI underscores this point emphatically. As this lawsuit unfolds, we have an opportunity to watch the rules and boundaries laid out for what constitutes legal usage of copyrighted data in LLM training corpora and the distinction between "learning" and "copying" when it comes to an LLM's response to inputs regarding such copyrighted material. Just like the Internet in the '90s, we'll likely see the legal responses and the technology itself shape each other as we hit gray area after gray area.
A Sample Basket
We've waxed philosophical about the puts and takes in this article, with some recommendations sprinkled throughout, but we owe it to the reader to summarize names we think make sense to hold as part of a thematic "AI bucket" for someone new to the space that believes in the macro opportunity we've (hopefully) laid out here. Without further ado:
Hardware names
-
Applied Materials - the most basic, most boring, most value-friendly name, without which nothing else can happen
-
Nvidia - Far from basic, far from boring, far from value-friendly, but impossible to ignore
Cloud Hyperscalers/Big Tech AI Shops
-
Microsoft - Cloud is coming on like gangbusters thanks to their AI bet, the OpenAI collaboration is paying off, and Copilot is arguably the most successful Applied AI product to date
-
Google - The DeepMind dynamo is producing, Google Cloud is powering a huge portion of the GenAI space, Gemini Ultra rolls out to the public later this year, it's hard not to see them on equal footing in this arena
Conclusion
As AI makes its way into the spotlight, there is understandably a lot of excitement, confusion and fear in the air. We have no doubt AI is here to stay, but what form it will take - and crucially, how that will translate into concrete business opportunities - is still fluid. What is not fluid is both the sheer computational demand of modern LLMs and the need for a streamlined, low-barrier ecosystem for developers and end-users to cost-effectively tap into these models. Here is where we see more substance for the average investor versus the hyperscaler arms races for bigger and better models or the startup rat race for the best applied technology.
Also, we're taking this opportunity to pivot our own area of focus to include generative AI as a major theme, both the fundamental and applied aspects. Betsy sees AI as a game-changer for the financial professional: for everything from parsing earnings data to performing financial analysis to handling bookkeeping, AI can unlock massive productivity boosts on tasks that might otherwise take entry-level workers hours or days to complete. She has also seen how AI has leveled the playing field for non-native English speakers struggling to communicate and get ahead in an English-centric business world. Derek still finds himself vexed by stories like our personal bookkeeping experience, despite nearly decades of experience screaming at compiler errors and segmentation faults, but even he is embracing the AI-powered future and keen to share more of what he sees with the investment community at large.
We hope you find our take on the landscape insightful and would be interested as well to hear what aspects you think will provide the biggest opportunities going forward.
For further details see:
The AI Trends (And Hype) For The Coming Year